
Исправљач (неуронске мреже)
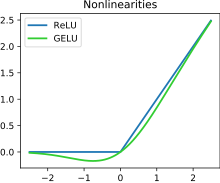
У контексту вештачких неуронских мрежа, функција активације исправљача или ReLU (Rectified Linear Unit) [1] [2] је активациона функција дефинисана као позитиван део свог аргумента:

где x представља улаз у неурон. Ово је иначе познато и као функција рампе и аналогно је полуталасном исправљању која је област у електротехници .
Ова активациона функција се почела појављивати у контексту екстракције визуелних карактеристика у хијерархијским неуронским мрежама почевши од краја 1960-их година. [3] [4] Касније се тврдило да има јаке биолошке мотиве и математичка оправдања. [5] 2011. године је откривено да омогућава бољу обуку дубљих мрежа, [6] у поређењу са широко коришћеним активационим функцијама од пре 2011. године, на пример, логистички сигмоид (који је инспирисан теоријом вероватноће ; погледајте и логистичку регресију ) и његов практичнији [7] еквивалент, хиперболичка тангента . Исправљач је, од 2017. године, најпопуларнија активациона функција за дубоке неуронске мреже . [8]
Исправљене линеарне јединице углавном налазе примену у компјутерском виду [9] и препознавању говора [10] [11] тако што користе дубоке неуронске мреже и рачунарску неуронауку . [12] [13] [14]
Предности
[уреди | уреди извор]- Ретка активација: На пример, у насумично иницијализованој мрежи, само око 50% скривених јединица је активирано (имају не-нултну излазну вредност).
- Боље ширење градијента: Мање проблема са нестајајућим градијентом у поређењу са функцијама сигмоидалне активације које се засићују у оба смера. [9]
- Ефикасно рачунање: Само поређење, сабирање и множење.
- Инваријантна размера: .

Активационе функције за исправљање су коришћене за раздвајање специфичне ексцитације и неспецифичних инхибиција у неурално апстрактној пирамиди, која је обучена на надгледајући начин да научи неколико задатака компјутерске визије. [15] У 2011. години, [9] показало се да употреба исправљача као нелинеарности омогућава обуку дубоко надгледаних неуронских мрежа без потребе за претходном обуком без надзора . Исправљене линеарне јединице, у поређењу са сигмоидном функцијом или сличним активационим функцијама, омогућавају бржи и ефикаснији тренинг дубоких неуронских архитектура на великим и сложеним скуповима података.
Потенцијални проблеми
[уреди | уреди извор]- Није диференцијабилан на нули; међутим, може се разликовати било где другде, а вредност деривата на нули може се произвољно изабрати да буде 0 или 1.
- Није нултно-центриран.
- Неограниченост
- Проблем умирања ReLU-а: ReLU (Rectified Linear Unit) неурони понекад могу бити гурнути у стања у којима постају неактивни за суштински све улазе. У овом стању, ниједан од градијената не тече уназад кроз неурон, тако да се неурон заглави у трајно неактивном стању и „умире“. Ово је облик проблема нестајања градијента . У неким случајевима, велики број неурона у мрежи може да се заглави у мртвим стањима, ефективно смањујући капацитет модела. Овај проблем се обично јавља када је стопа учења постављена превисоко. Може се ублажити коришћењем пропуштајућих ReLU-ова, који додељују мали позитиван нагиб за х < 0; међутим, перформансе су смањене.
Варијанте
[уреди | уреди извор]Комадично-линеарне варијанте
[уреди | уреди извор]Пропуштајући ReLU
[уреди | уреди извор]Пропуштајући ReLU-ови дозвољавају мали, позитиван градијент када јединица није активна. Следећа функција гласи: [11]

Параметризован ReLU
[уреди | уреди извор]Параметризовани ReLU-ови (PReLUs) развијају ову идеју даље тако што претварају коефицијент цурења у параметар који се учи заједно са другим параметрима неуронске мреже. [16]

Имајте на уму да су за а ≤ 1 ове две функције еквивалентне максималној вредности функције која се налази испод

и самим тим имају везу са "maxout" мрежама. [17]
Друге нелинеарне варијанте
[уреди | уреди извор]Гаусова линеарна јединица грешке (GELU)
[уреди | уреди извор]GELU представља глатку апроксимацију исправљача. Има немонотонски „bump“ када је х < 0, и служи као подразумевана активација за моделе као што је БЕРТ . [18]
,

где Φ( х ) представља кумулативна функција расподеле стандардне нормалне расподеле .
Ова активациона функција је илустрована на слици која се налази на почетку овог чланка.
SiLU
[уреди | уреди извор]SiLU (Сигмоидова Линеарна Јединица) или функција swish [19] је још једна глатка апроксимација која је први пут скована у ГЕЛУ раду. [20]

где је сигмоидна функција .

Softplus
[уреди | уреди извор]Апроксимација исправљача глатког и лаганог облика представља наведену аналитичку функцију која је представљена функцијом испод:

и та функција се назива softplus [21] [9] или SmoothReLU . [22] За велике негативне вредности је отприлике једнако дакле нешто изнад 0, док за велике позитивне вредности је отприлике једнако тек мало изнад .



Параметар оштрине може бити укључено:


Извод softplus-а једнак је логистичкој функцији . Почевши од параметарске верзије,

Логистичка сигмоидна функција је приближна апроксимација извода исправљача, односно Хевисајдове корак функције .
Мултиваријабилна генерализација softplus-а са једном променљивом је [1]LogSumExp са првим аргументом који је постављен на нулу:

Функција LogSumExp је

а његов градијент представља [2]softmax ; softmax са првим аргументом који је постављен на нулу је мултиваријабилна генерализација логистичке функције. И LogSumExp и softmax се користе у машинском учењу.
ELU
[уреди | уреди извор]Експоненцијалне линеарне јединице покушавају да учине средње активације буду ближе нули, што убрзава процес учења. Показало се да ELU могу постићи већу тачност класификације од ReLU-ова. [23]

где је хиперпараметар који треба подесити, и је ограничење.


ELU се може посматрати као да је изглађена верзија помереног ReLU (SReLU), који има облик функције с обзиром на исто тумачење .

Mish
[уреди | уреди извор]Mish функција се такође може икористити као апроксимација исправљача глатког облика. [24] Дефинише се као

где представља хиперболичну тангенту и је [3]softplus функција.


Миш је немонотон и самосталан . [25] Инспирисан је [4]Swish -ом, који је варијанта ReLU-а . [25]
Види још
[уреди | уреди извор]- ^ Brownlee, Jason (8. 1. 2019). „A Gentle Introduction to the Rectified Linear Unit (ReLU)”. Machine Learning Mastery. Приступљено 8. 4. 2021.
- ^ Liu, Danqing (30. 11. 2017). „A Practical Guide to ReLU”. Medium (на језику: енглески). Приступљено 8. 4. 2021.
- ^ Fukushima, K. (1969). „Visual feature extraction by a multilayered network of analog threshold elements”. IEEE Transactions on Systems Science and Cybernetics. 5 (4): 322—333. doi:10.1109/TSSC.1969.300225.
- ^ Fukushima, K.; Miyake, S. (1982). „Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition.”. In Competition and Cooperation in Neural Nets. Lecture Notes in Biomathematics. Springer. 45: 267—285. ISBN 978-3-540-11574-8. doi:10.1007/978-3-642-46466-9_18.
- ^ Hahnloser, R.; Sarpeshkar, R.; Mahowald, M. A.; Douglas, R. J.; Seung, H. S. (2000). „Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit”. Nature. 405 (6789): 947—951. Bibcode:2000Natur.405..947H. PMID 10879535. doi:10.1038/35016072.
- ^ . Архивирано из оригинала
|archive-url=захтева|url=(помоћ)|archive-url=захтева|archive-date=(помоћ). г. Недостаје или је празан параметар|title=(помоћ) - ^ „Efficient BackProp” (PDF). Neural Networks: Tricks of the Trade. Springer. 1998. Архивирано из оригинала (PDF) 31. 08. 2018. г. Приступљено 01. 09. 2022.
- ^ Ramachandran, Prajit; Barret, Zoph (16. 10. 2017). „Searching for Activation Functions”. arXiv:1710.05941
 [cs.NE].
[cs.NE].
- ^ а б в г . Архивирано из оригинала
|archive-url=захтева|url=(помоћ)|archive-url=захтева|archive-date=(помоћ). г. Недостаје или је празан параметар|title=(помоћ)Xavier Glorot, Antoine Bordes and Yoshua Bengio (2011). Deep sparse rectifier neural networks Архивирано на сајту Wayback Machine (13. децембар 2016) (PDF). AISTATS.Rectifier and softplus activation functions. The second one is a smooth version of the first.
{{cite conference}}: CS1 maint: uses authors parameter (link) - ^ . Архивирано из оригинала
|archive-url=захтева|url=(помоћ)|archive-url=захтева|archive-date=(помоћ). г. Недостаје или је празан параметар|title=(помоћ) - ^ а б Andrew L. Maas, Awni Y. Hannun, Andrew Y. Ng (2014). Rectifier Nonlinearities Improve Neural Network Acoustic Models.
- ^ Hansel, D.; van Vreeswijk, C. (2002). „How noise contributes to contrast invariance of orientation tuning in cat visual cortex”. J. Neurosci. 22 (12): 5118—5128. PMC 6757721 . PMID 12077207. doi:10.1523/JNEUROSCI.22-12-05118.2002.
- ^ Kadmon, Jonathan; Sompolinsky, Haim (2015-11-19). „Transition to Chaos in Random Neuronal Networks”. Physical Review X. 5 (4): 041030. Bibcode:2015PhRvX...5d1030K. arXiv:1508.06486 . doi:10.1103/PhysRevX.5.041030.
- ^ Engelken, Rainer; Wolf, Fred (2020-06-03). „Lyapunov spectra of chaotic recurrent neural networks”. arXiv:2006.02427 [nlin.CD].
- ^ Behnke, Sven (2003). Hierarchical Neural Networks for Image Interpretation. Lecture Notes in Computer Science. 2766. Springer. ISBN 978-3-540-40722-5. doi:10.1007/b11963.
- ^ He, Kaiming; Zhang, Xiangyu. „Delving Deep into Rectifiers: Surpassing Human-Level Performance on Image Net Classification”. arXiv:1502.01852 [cs.CV].
- ^ He, Kaiming; Zhang, Xiangyu. „Delving Deep into Rectifiers: Surpassing Human-Level Performance on Image Net Classification”. arXiv:1502.01852 [cs.CV].
- ^ Hendrycks, Dan; Gimpel, Kevin. „Gaussian Error Linear Units (GELUs)”. arXiv:1606.08415 [cs.LG].
- ^ Diganta Misra (23. 8. 2019), Mish: A Self Regularized Non-Monotonic Activation Function (PDF), arXiv:1908.08681v1 , Приступљено 26. 3. 2022
- ^ Hendrycks, Dan; Gimpel, Kevin. „Gaussian Error Linear Units (GELUs)”. arXiv:1606.08415 [cs.LG].
- ^ Dugas, Charles; Bengio, Yoshua; Bélisle, François; Nadeau, Claude; Garcia, René (2000-01-01). „Incorporating second-order functional knowledge for better option pricing” (PDF). Proceedings of the 13th International Conference on Neural Information Processing Systems (NIPS'00). MIT Press: 451—457. „Since the sigmoid h has a positive first derivative, its primitive, which we call softplus, is convex.”
- ^ „Smooth Rectifier Linear Unit (SmoothReLU) Forward Layer”. Developer Guide for Intel Data Analytics Acceleration Library (на језику: енглески). 2017. Архивирано из оригинала 05. 12. 2021. г. Приступљено 2018-12-04.
- ^ Clevert, Djork-Arné; Unterthiner, Thomas. „Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)”. arXiv:1511.07289 [cs.LG].
- ^ Diganta Misra (23. 8. 2019), Mish: A Self Regularized Non-Monotonic Activation Function (PDF), arXiv:1908.08681v1 , Приступљено 26. 3. 2022
- ^ а б Shaw, Sweta (2020-05-10). „Activation Functions Compared with Experiments”. W&B (на језику: енглески). Приступљено 2022-07-11.